
Animated
 Code (coming soon)
Code (coming soon)
 Visit DiFaReli
Visit DiFaReli
by improving shadow consistency and enabling relighting in a single network pass.
Animated
We introduce a novel approach to single-view face relighting in the wild, addressing challenges such as global illumination and cast shadows. A common scheme in recent methods involves intrinsically decomposing an input image into 3D shape, albedo, and lighting, then recomposing it with the target lighting. However, estimating these components is error-prone and requires many training examples with ground-truth lighting to generalize well. Our work bypasses the need for accurate intrinsic estimation and can be trained solely on 2D images without any light stage data, relit pairs, multi-view images, or lighting ground truth. Our key idea is to leverage a conditional diffusion implicit model (DDIM) for decoding a disentangled light encoding along with other encodings related to 3D shape and facial identity inferred from off-the-shelf estimators. We propose a novel conditioning technique that simplifies modeling the complex interaction between light and geometry. It uses a rendered shading reference along with a shadow map, inferred using a simple and effective technique, to spatially modulate the DDIM. Moreover, we propose a single-shot relighting framework that requires just one network pass, given pre-processed data, and even outperforms the teacher model across all metrics. Our method realistically relights in-the-wild images with temporally consistent cast shadows under varying lighting conditions. We achieve state-of-the-art performance on the standard benchmark Multi-PIE and rank highest in user studies.
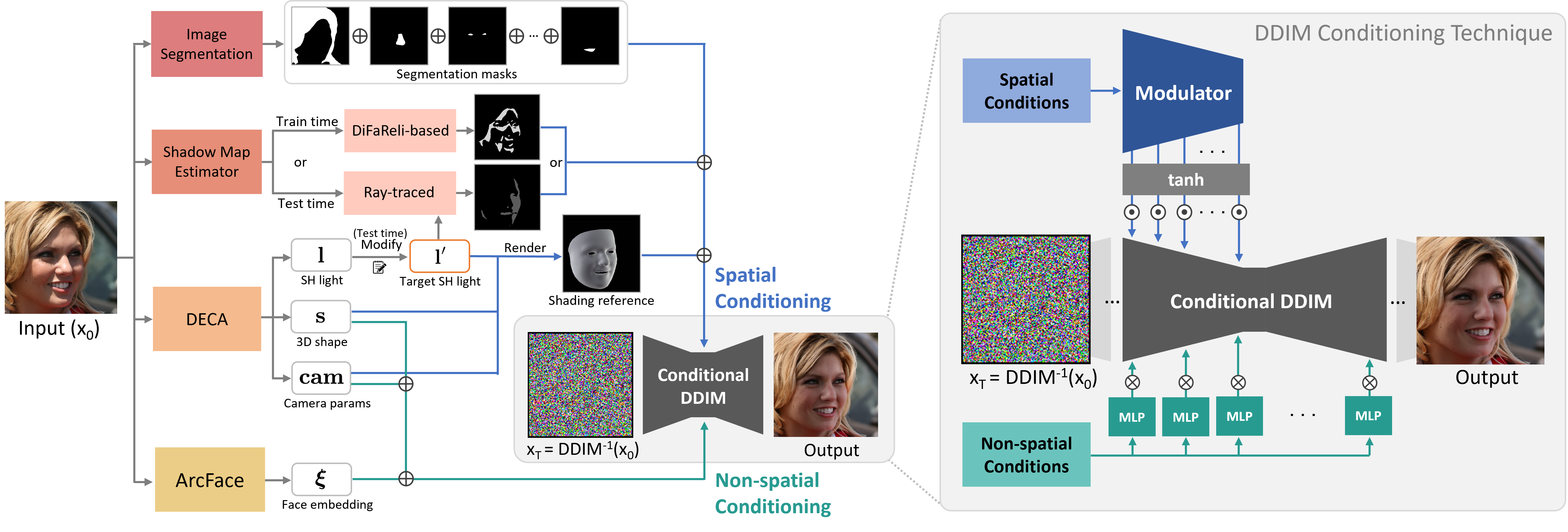
The general idea of our method is simple: we first encode an input image into a feature vector that disentangles the lighting information from all other information in the image, then modify the lighting information in the vector and decode it. The challenge here is how to disentangle it well enough that the decoding will only affect the shading and not the person’s shape or identity. Our key idea is to leverage a conditional diffusion implicit model with a novel conditioning technique for this task and learn the complex light interactions implicitly via the DDIM trained solely on a 2D face dataset.
In particular, we use off-the-shelf estimators (DECA, Arcface, and BiSeNet) to encode each training image into encodings of light, shape, camera, face embedding, and segmentation masks. Additionally, we infer a shadow map using a novel DiFaReli-based technique, which relies on DiffAE. We then train a DDIM decoder conditioned on these encodings. To relight an input face image, we reverse the generative process of the DDIM conditioned on the encodings of the input image to obtain xT. Then, we modify the light encoding and decode xT back to a relit output.
We present relighting results featuring diverse lighting paths. These input images contain existing strong highlights and cast shadows, a wide range of head poses, or facial makeup and accessories. On the left, we visualize the approximate location of the dominant light source, where the size of the red circle represents the area of the light source. Smaller areas produce sharper cast shadows, while larger areas create more diffuse appearances.
Our method produces the most consistent cast shadows and realistic relighting compared to four state-of-the-art methods, across diverse subjects with varying head poses and lighting conditions.
The shadow map and shading reference are provided in the rightmost column (Cond.).
We can adjust the intensity of cast shadows by modifying the shadow map values. Our method can effectively handle shadows cast by facial features (e.g., nose, cheeks, brow ridge), eyeglasses, and hats, making the face appear more diffuse or with more intense shadows.
@misc{ponglertnapakorn2025difarelidiffusionfacerelighting,
title={DiFaReli++: Diffusion Face Relighting with Consistent Cast Shadows},
author={Ponglertnapakorn, Puntawat and Tritrong, Nontawat and Suwajanakorn, Supasorn},
year={2025},
eprint={2304.09479},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2304.09479}
}
Acknowledgements: This website was built upon templates borrowed from DreamFusion and EG3D.



